Take a good look at the following two sentences. Which is correct?
1. Serum was incubated at 37 °C. 2. Serum was incubated at 37 ℃.
They look exactly the same, you might say. If you look very closely, however, you will notice a slight difference between the two sentences in the symbols for “degrees Celsius”.
In sentence 1, “degrees Celsius” is expressed correctly using two characters – the degree symbol ° and the upper-case letter C.
In sentence 2, however, “degrees Celsius” is expressed incorrectly using one single character that combines both the degree symbol and the letter C. This type of character is referred to as a double-byte character; a character made up of two bytes.
Double-byte or “zenkaku” characters are used for languages that are written using a large number of characters, such as Chinese and Japanese. Single-byte or “hankaku” characters, on the other hand, are used for languages that require only a small number of characters, such as English. The maximum number of characters that can be represented with one byte is 256, while two bytes can represent up to 65,536 characters.
Needless to say, the character for “degrees Celsius” used in the second sentence does not exist in English and should not be used when writing English texts. It is tempting, however, for Japanese authors to enter symbols such as °C using one double-byte character when typing an English text.
Inserting the symbol ° is indeed somewhat bothersome. In Word, for instance, it requires clicking the “Insert” tab, selecting “Symbols”, then “More Symbols”, and then finding the appropriate symbol from a large collection of characters, some looking very similar to °.
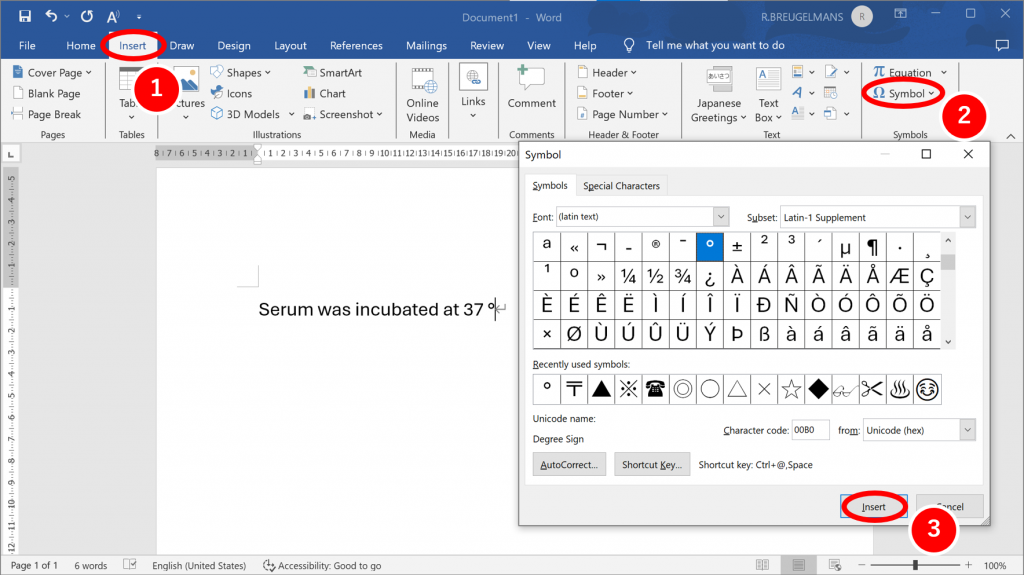
On a Japanese computer, however, all one needs to do to insert the zenkaku character for “degrees Celsius” is to type the Japanese word “do” (meaning degree), and hit a special “Convert” key on the keyboard. That’s it. So much easier and faster! Double-byte characters therefore tend to slip in quite frequently.
A problem with sending a file which has zenkaku characters is that they may get garbled resulting in a very unprofessional look. No one wants to see Œâ®¾ã› when trying to read your work! Although the near-universal adoption of Unicode makes this less of a problem than it used to be, it is still necessary to use only characters that are acceptable for use in English, and Japanese authors should check the final draft of their paper before submission to make sure that no inappropriate zenkaku characters are present.
Degrees Celsius © 2025 by Raoul Breugelmans is licensed under CC BY-ND 4.0 ![]()
![]()
![]()